用 Acrobat 修复因缺少内嵌字体而乱码的 PDF 文件
前言
最近在阅读一本电子书的时候发现 PDF 文件中只要是英文、数字、空格的位置都是乱码,影响阅读。这应该是 PDF 文档没有将所需要的所有字体内嵌到文档中,缺少字体导致的。比如某东的电子发票在不同的 PDF 阅读软件上打开会出现不同的字体。
这里分享一下修复文档的整个过程。

需要软件
- Adobe Acrobat Pro DC 2020
- 文件中尚未内嵌的字体(方正EU系列)
检查字体缺失
PDF 文档出现乱码,首先要检查是否是缺失字体。用 Acrobat 打开 PDF 文件,菜单栏选择“文件”、“属性”、“字体”选项卡,可以看到该 PDF 文档中使用的所有字体。
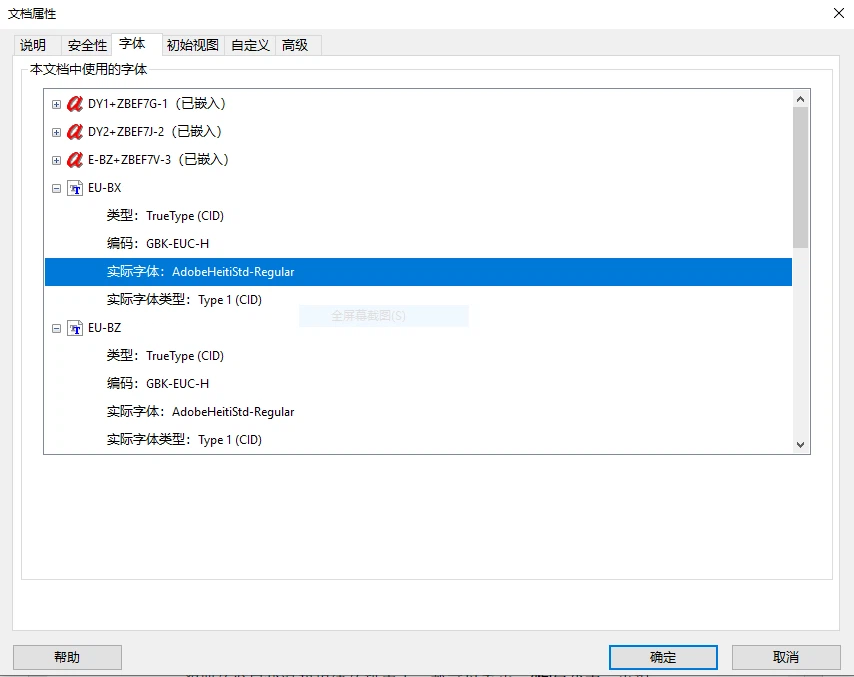 已内嵌文档的字体会显示“(已嵌入)”,未嵌入的字体,如图中的
已内嵌文档的字体会显示“(已嵌入)”,未嵌入的字体,如图中的EU-BX.ttf字体是方正的西文“白斜”字体,由于不同的 PDF 阅读器遇到字体缺失后会选择一个缺省字体替代,而不同字体的字符集不同,所以会出现乱码的情况。
缺失字体修复
首先找到缺失的字体文件,安装到电脑中。一般来说,安装好缺失字体后再用 PDF 阅读器查看文档就不会乱码,文档恢复正常。但是 PDF 文件是跨平台的便携式文档,如果要在其它设备上不出问题还是要将所需的字体全部嵌入。
回到 Acrobat 的“主页”,添加“印刷制作”工具。
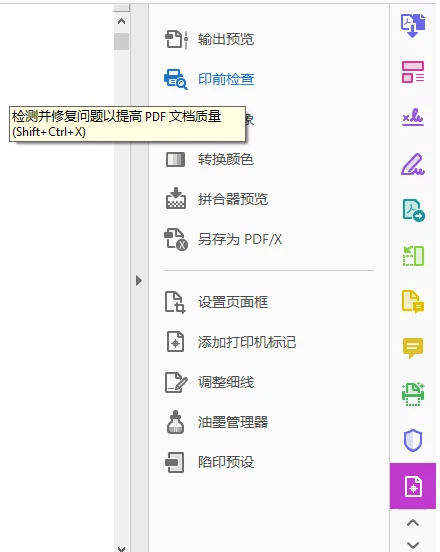
 打开要修复的文件,在右侧工具栏选择“印刷制作”、“印前检查”。
打开要修复的文件,在右侧工具栏选择“印刷制作”、“印前检查”。
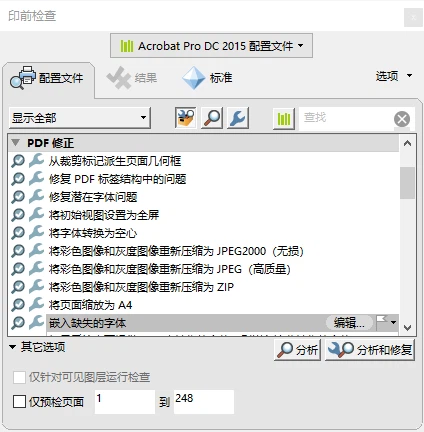
“印前检查”选择“PDF 修正”、“嵌入缺失的字体”,然后点击“分析和修复”,保存修复后的文件,稍等一会。
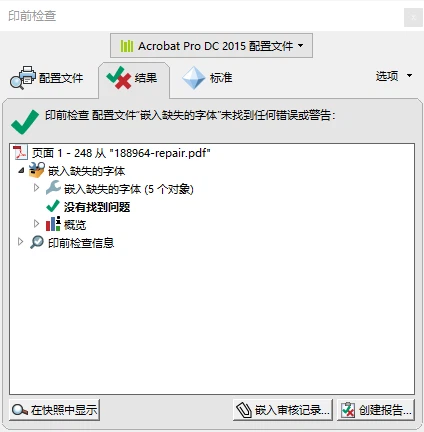
 经过一小段时间的修复,如果最终的结果是“没有找到问题”说明文件已成功修复。
经过一小段时间的修复,如果最终的结果是“没有找到问题”说明文件已成功修复。
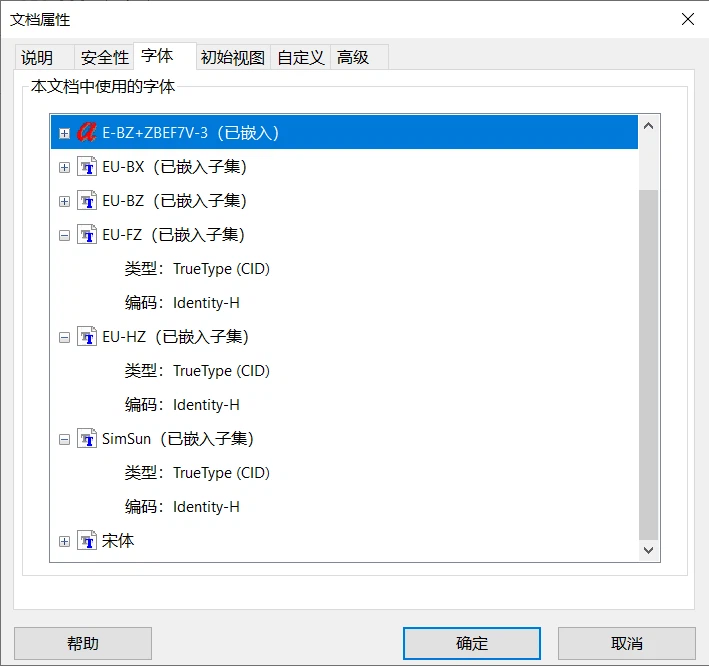
 打开修复后的文件,查看文档属性,缺失的字体已经嵌入,可以正常显示。
打开修复后的文件,查看文档属性,缺失的字体已经嵌入,可以正常显示。
 修复前后的扉页
修复前后的扉页

吐槽
PDF 文件格式相当灵活,各种编译器、阅读器在实现上没有统一的标准,所以导致 PDF 文件容易出现各种奇奇怪怪的问题。比如某文档扫描 App 生成的 PDF 无法用 Python 的 PyPDF 编辑,报错原因是页码错误。经过我测试发现是 PDF 不符合标准,将文件转换成 PDF/A 标准的格式就恢复正常了。